Distributed
Hash Tables
Concise & Simple
(A minor obsession)
Concise & Simple
(A minor obsession)
Nicholas H.Tollervey
 ntoll.org
/
ntoll.org
/
 ntoll@ntoll.org
/
ntoll@ntoll.org
/
 @ntoll
@ntoll
HIGH LEVEL VIEW

(I'm glossing over a lot here...)
Hash Table = dict (in Python)
>>> home = {}
>>> home['ntoll'] = 'Towcester'
>>> home['voidspace'] = 'Bugbrook'
>>> home['pinner'] = 'Coventry'
>>> home
{
'ntoll': 'Towcester',
'voidspace': 'Bugbrook',
'pinner': 'Coventry'
}
>>> home['ntoll']
'Towcester'
A very simple key / value data store.
Distributed

Decentralized
A distributed
hash table (DHT) is a peer-to-peer
key / value data store
Why?
- No single point of failure or inadvertent point of control (e.g. no need for DNS).
- Scale to huge number of nodes (redundancy++).
- Relatively efficient.
- Good handling of fluid network membership.
- Solid foundational infrastructure for more complex services (e.g. the drogulus, distributed file systems, CDNs, p2p file sharing).
- Tested in the real world (Bittorrent, Freenet and others).
How..?
What the rest of the talk is about:
- The DHT has a key space the size of the output range of its hashing function (e.g. SHA512).
- Each node has a unique ID (a hash).
- Each key is a hash.
- Nodes store values whose keys are close to the node's ID.
- Nodes keep track of peers in a routing table.
- A recursive lookup function is used to find the correct node[s].
Hashing
>>> import requests
>>> response = requests.get(
'http://www.gutenberg.org/ebooks/2600.txt.utf-8')
>>> war_and_peace = response.content
>>> len(war_and_peace)
3291641
>>> from hashlib import sha1
>>> hash = sha1(war_and_peace)
>>> hash.hexdigest()
'ee9fe1af40a27e58ca32dce32c891dce2885bbcb'
>>> int(hash.hexdigest().encode('hex'), 16)
8460127932676481751312505548999589516107164899634142
19229096415778905956014446754451978211976034L
A hash is just a number.
ee9fe1af40a27e58ca32dce32c891dce2885bbcb

Good Hash functions...
- Deterministically generate small-ish values from seed data.
- Cannot be reversed.
- Generate different values from different seed data.
- Uniformly distribute values in the output range.
- Attempt to avoid collisions (that are, unfortunately, inevitable).
Hashing for Nodes and Keys
(Location, Location, Location)
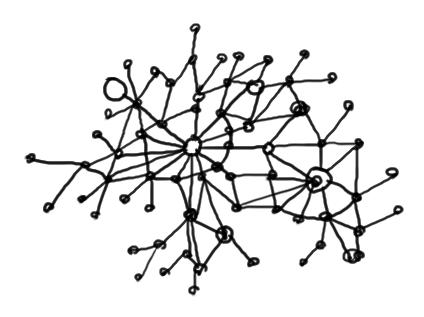
A clock face of nodes
Node's ID (location) is derived from Hash
Items are a Key / Value Pair
>>> from hashlib import sha1
>>> item = {
... 'my_key': 'Some value I want to store'
... }
>>> sha1('my_key').hexdigest()
'0f7da3f82f86e5ea63d3ac270f091af4bcfa819a'
The key is turned into a hash. The value is stored at nodes whose IDs are close to the location of the hash of the key.
Aardvark belongs...

... under "A"

But, Zebra belongs...

... under "Z"

Tracking via the Routing Table
Interactions give tracking data

(ID, IP address and port etc...)
Peers stored in fixed size buckets
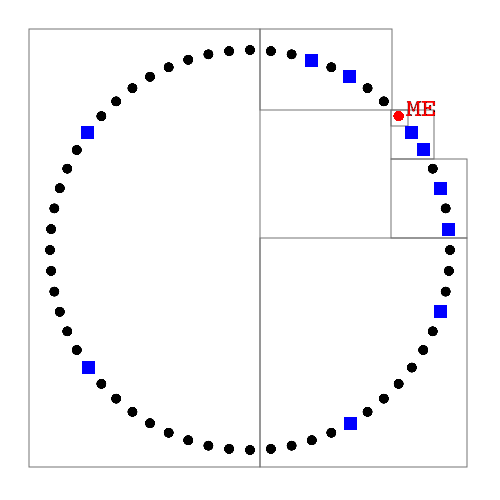
Buckets contain the same number of peers
Buckets cover a smaller range the closer to the local node thay are
Ergo, the local node knows more closer nodes
Peers stored in fixed size buckets
Ignore unresponsive peers
Refresh the Routing Table
Re-publish items
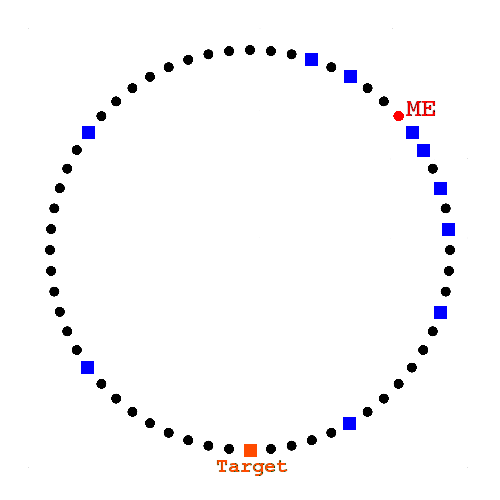
Recursive Lookup

Six degrees of separation
Ask closest known peers
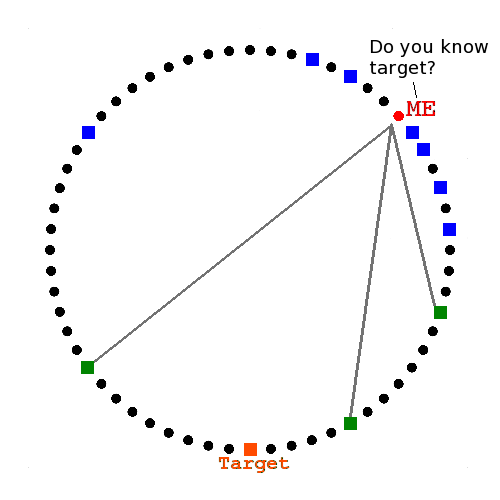
They reply with closer peers
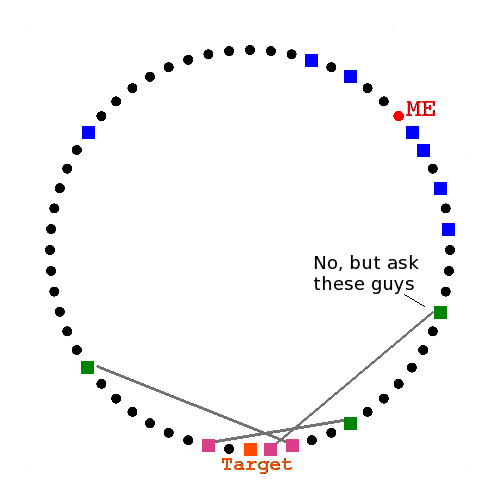
They reply with the target
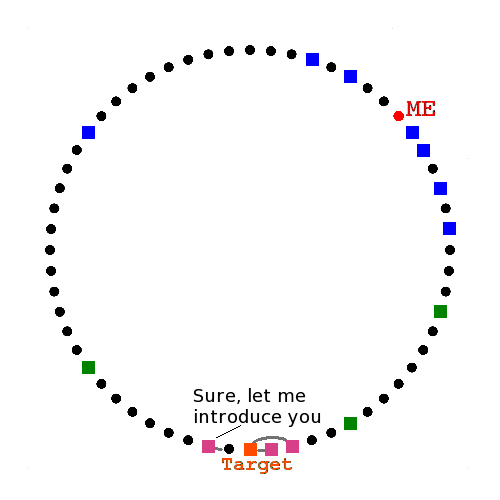
GET() & SET() require a lookup.
All interactions are asynchronous.
That's it!
(But I'm only scratching the surface)
Find Out More
Image Credits
Licensed under CC BY 2.0
Questions..?
The source for this presentation can be found online here: